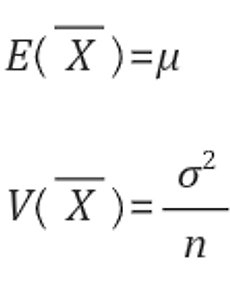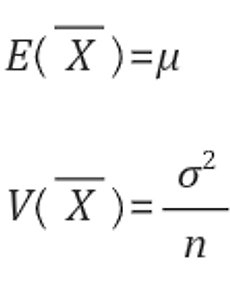 표준오차,표준편차,표본평균,모평균 통계용어 정리
'모집단'이 있다 모집단의 평균을 M(뮤) , 표준편차를 S(시그마)라고 하자 모집단의 평균을 '추정'하기 위해 모집단에서 크기가 n인 표본을 추출, 이를 표본1이라고 하자 표본1의 평균은 m1 m1, m2, m3, m4, .... 이 표본평균은 다음과 같은 성질이 성립한다. 1) 표본평균의 평균이 모평균과 같다 (표본들 각각의 평균값들을 전부더해서 n만큼 나누면 모집단의 평균,모평균과 같아진다) 2) 표본 평균의 분산이 모분산을 n으로 나눈것과 같다 (천천히 한단어씩 이해하면서 넘어가야한다 . 뒤에서 혼돈이 올수있음) 분산 V(X) = E((X-M)**2) 분산 V(X) = S(X)**2 이 때 표본평균의 표준편차를 '표준오차'라고 한다 출처 : hsm-edu.tistory.com/794 표준오차가 뭔..
2021. 1. 7.
표준오차,표준편차,표본평균,모평균 통계용어 정리
'모집단'이 있다 모집단의 평균을 M(뮤) , 표준편차를 S(시그마)라고 하자 모집단의 평균을 '추정'하기 위해 모집단에서 크기가 n인 표본을 추출, 이를 표본1이라고 하자 표본1의 평균은 m1 m1, m2, m3, m4, .... 이 표본평균은 다음과 같은 성질이 성립한다. 1) 표본평균의 평균이 모평균과 같다 (표본들 각각의 평균값들을 전부더해서 n만큼 나누면 모집단의 평균,모평균과 같아진다) 2) 표본 평균의 분산이 모분산을 n으로 나눈것과 같다 (천천히 한단어씩 이해하면서 넘어가야한다 . 뒤에서 혼돈이 올수있음) 분산 V(X) = E((X-M)**2) 분산 V(X) = S(X)**2 이 때 표본평균의 표준편차를 '표준오차'라고 한다 출처 : hsm-edu.tistory.com/794 표준오차가 뭔..
2021. 1. 7.