Training & Test Data
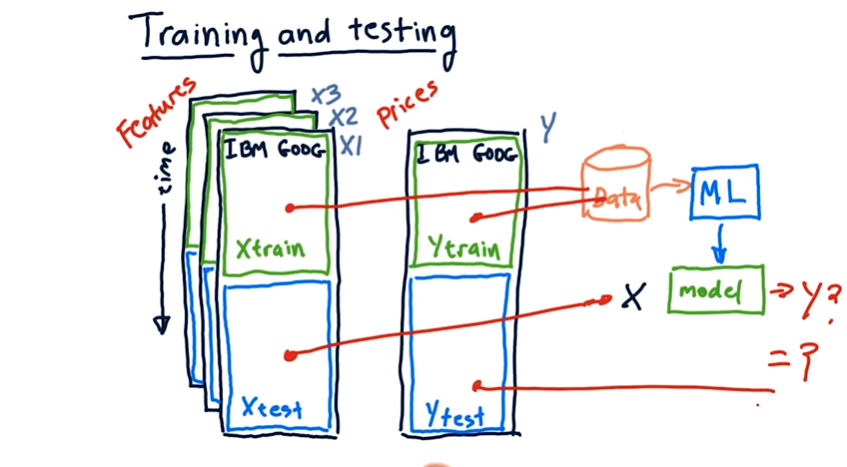
주어진 데이터를 train 과 test 데이터 나눈 뒤
train 데이터를 기반으로 머신러닝 모델 학습
그 후 test 데이터를 활용하여 만든 머신러닝 모델이 맞는지 확인
가급적이면
오래된 데이터를 train으로 쓰고 최신 데이터를 test로 쓴다고 한다
(시계열이 중요한 데이터라면)
출처 : youtu.be/P2NqrFp8usY
Machine Learning Fundamentals
Bias & Variance


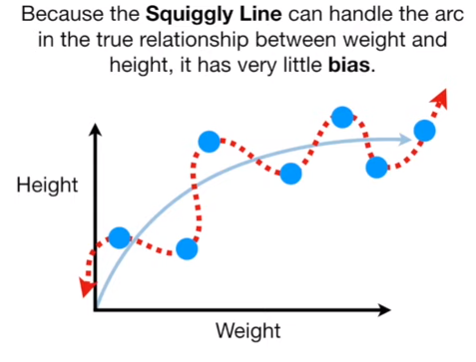



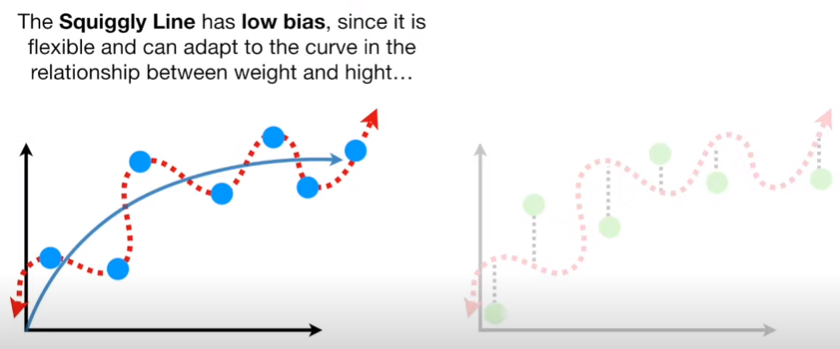


머신러닝을 통해
low bias and low variance
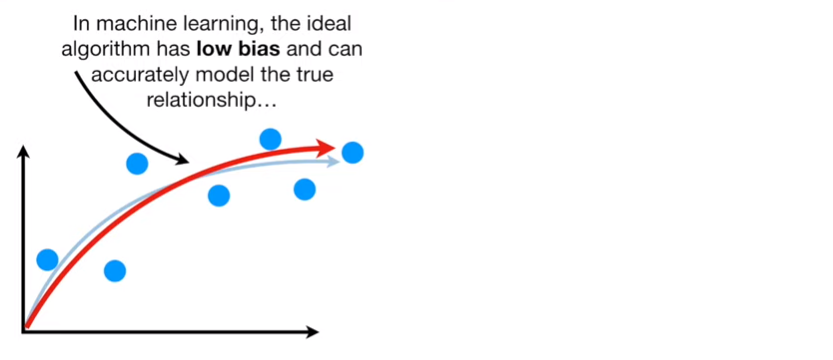

분산 / 편향 트레이드오프
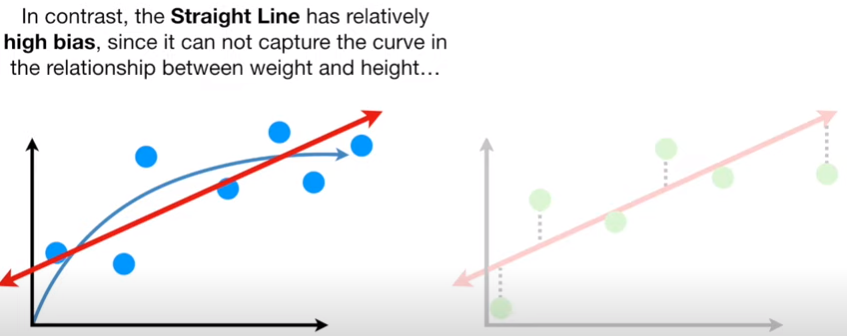
복잡한 모델을 써야하는데 , 간단한 모델을 쓰는 경우 '편향에러가 증가'
필요보다 더 과도하게 복잡한 모델을 사용한 경우 '분산에러가 증가'
즉, 모델의 복잡도가 단순할수록 편향에러 증가 , 분산에러 감소
모델의 복잡도가 복잡할수록 편향에러 감소 , 분산에러 증가

편향 (bias) 와 분산 (variance)
편향은 학습 알고리즘에서 잘못된 가정을 했을 때 발생하는 오차이다.
높은 편향값은 알고리즘이 데이터의 특징과 결과물과의 적절한 관계를 놓치게 만드는 과소적합(underfitting) 문제를 발생 시킨다.
분산은 트레이닝 셋에 내재된 작은 변동(fluctuation) 때문에 발생하는 오차이다.
높은 분산값은 큰 노이즈까지 모델링에 포함시키는 과적합(overfitting) 문제를 발생 시킨다.
편향-분산 트레이드오프 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 둘러보기로 가기 검색하러 가기 함수와 노이지 데이터 함수(빨간색)가 방사상 기저 함수(radial basis functions)를 사용하여 근사(approximate)된 것이다. 노이지 데이터
ko.wikipedia.org
출처 : www.opentutorials.org/module/3653/22071
Bias and Variance (편향과 분산) - 한 페이지 머신러닝
편향? 분산? 머신러닝과 무슨 상관인가 지도학습(Supervised Learning)에 대해서 이야기를 할 때는 사람이 정해준 정답이 있고, 컴퓨터가 그 정답을 잘 맞추는 방향으로 훈련(training)을 시킵니다.
www.opentutorials.org
출처 : youtu.be/EuBBz3bI-aA
'AI월드 > ⚙️AI BOOTCAMP_Section 2' 카테고리의 다른 글
| Bias/Variance/편향과분산, 한번더_Day22(5) (0) | 2021.01.30 |
|---|---|
| 과적합(Overfitting)과 과소적합(Underfitting)_Day22(4) (0) | 2021.01.29 |
| Mean Square Error,평균 제곱근 편차,잔차와오차_Day22(2) (0) | 2021.01.29 |
| R Squared 계산방법 , R 스퀘어, 결정계수_Day22 (0) | 2021.01.29 |
| 단순선형회귀,Simple Linear Regression_Day21(3) (0) | 2021.01.28 |




댓글