

결정트리 classification의 결과는 카테고리형이 될수도 , 숫자형이 될수도 있다

좌측의 질문순서와 우측의 질문순서가 꼭 같을 필요 없다
(우측에 도넛먹는지 물어봤다고 좌측에 도넛먹는지 먼저 물어볼 필요 없다는 뜻)

Rood Node : The Root : 가장 상단의 시작점 (화살을 주기 시작하는 점)
Internal Nodes : Nodes : 중간 지점의 연결점 (화살을 받기도 하고 , 주기도 한다)
Leaf Nodes : Leaves : 가장 마지막의 최종점 ( 화살을 받기만 한다) = classification의 결과



(좌) 좌측에 주어진 데이터로 결정트리를 만들려고 한다. 어떤 조건이 가장 상단에 들어가야 하는가?
(우) 각 조건별 타겟값의 분포를 보면 어느하나 100%로 구분되는 상황이 없다 (모두 확률적으로 나뉘어있다)
이 상황을 impure (불순한) 이라 하고 , impurity(불순물) 비교를 통해 어떤 분류가 가장 최선인지 결정해야 한다


가장 유명하고 쉬운 방법이 "Gini"
1) 1 - (yes의 가능성)**2 - (no의가능성)**2
2) 좌측의 gini계수는 0.395 , 우측의 gini계수는 0.336
총 gini계수는 좌측과 우측의 합인 0.731이 되어야 하나
좌측의 환자수와 우측의 환자수가 다르기 때문에 가중치를 적용한 뒤 총 gini계수를 구한다




각각의 특성값에 따른 Gini 계수를 모두 구해본 결과
0.360의 '혈액순환이 잘되는지' 항목이 가장 낮은 수치를 기록
해당 특성을 최상단 Root Node 에 두기로 한다
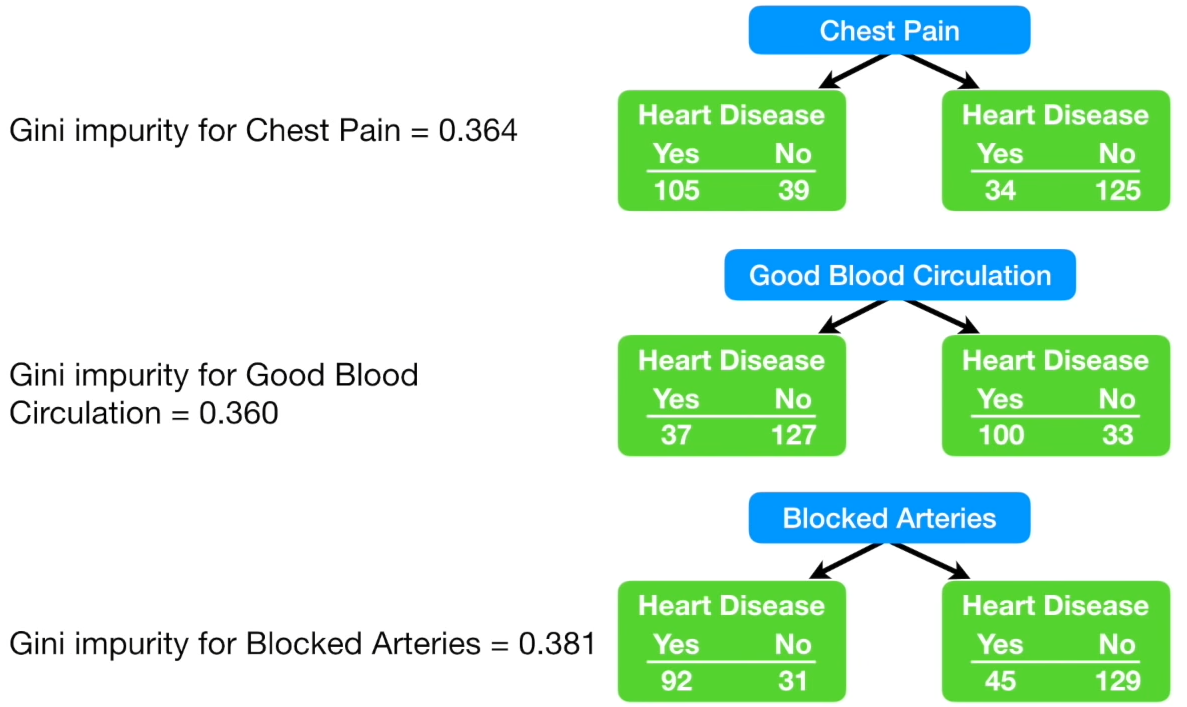

'Good blood circulation' 항목을 최상단에 두고 난뒤
나뉜 값을 기준으로 다시 'check pain'과 'blocked arteries'를 위에 방법과 동일하게 비교한다


(좌)
다음 항목인 chest pain 을 분류할때
좌측은 gini 계수 비교를 통해 chest pain 으로 다시 나누는게 더 좋지만
우측 13/102의 경우
체스트페인으로 나누면 gini 계수는 0.29
나누지않고 현재의 지니 계수는 0.2
즉 나누지않고 지금 13/102로 두는게 더 낮은 지니계수를 나타내므로 , 지금이 최종값
(우)
동일한 방법으로 gini 계수 비교를 통해 node 나누고
최종 leaf node 까지 동일한 방법으로 계산


랭크 데이터 또는 카테고리 데이터로 결정트리를 만드는 방법은 ?


출처 : youtu.be/7VeUPuFGJHk
'AI월드 > ⚙️AI BOOTCAMP_Section 2' 카테고리의 다른 글
| Confusion Matrix, 혼동행렬_Day28 (0) | 2021.02.08 |
|---|---|
| Random Forest,랜덤포레스트_Day27 (0) | 2021.02.05 |
| Logistic Regression,Maximum Likelihood_Day24(4) (0) | 2021.02.04 |
| Logistic Regression ,Coefficients_Day24(3) (0) | 2021.02.04 |
| Logistic Regression,로지스틱_Day24(2) (0) | 2021.02.04 |




댓글