
목차
<NN>
- 1-1. 퍼셉트론, 인공신경망
- 1-2. 역전파, 경사하강법
- 1-3. 신경망 프레임워크, 학습규제
- 1-4. 파라미터 튜닝, 실험기록
<NLP>
- 2-1. 텍스트 전처리
- 2-2. 텍스트 벡터화
- 2-3. Word2Vec, RNN, LSTM, GRU
- 2-4. Attention과 Transformer, GPT, BERT
<CNN>
- 3-1. CNN
- 3-2. Image Segmenatation
- 3-3. AutoEncoder
- 3-4. GAN
NN
1-1. 퍼셉트론, 인공신경망
(1) 퍼셉트론
: 퍼셉트론은 다수의 신호를 입력으로 받아 하나의 신호를 출력하는 기본 단위 (아래 이미지)

(2) 신경망
: 신경망은 '노드'들이 '가중치'로 연결되어 입력값을 출력값으로 내보내는 함수
: 이 가중치를 찾는 과정을 학습(training, learning)이라고 하며 가중치는 예측에 사용
: 아래 그림과 같이 기본적으로 입력층(Input) , 은닉층(Hidden) , 출력층(Output)으로 나뉨
: 출력층
- 회귀 문제에서 예측할 목표 변수가 실수값인 경우 활성화함수가 필요하지 않으며 출력노드의 수는 출력변수의 갯수와 같다.
- 이진 분류(binary classification) 문제의 경우 시그모이드(sigmoid) 함수를 사용해서 출력을 확률값으로 변환하여 부류(label)를 결정하도록 한다.
- 다중클래스(multi-class)를 분류하는 경우 출력층 노드가 부류(label) 수 만큼 존재하며 소프트맥스(softmax) 함수를 활성화 함수로 사용한다.

예제) tesorflow 신경망 , 데이터셋 : mnist
https://github.com/khalidpark/deeplearning_whitepaper/blob/main/deep_learning_whitepaper_1.ipynb
khalidpark/deeplearning_whitepaper
Examples for the Deep Learning White Paper. Contribute to khalidpark/deeplearning_whitepaper development by creating an account on GitHub.
github.com
(3) 딥러닝(인공신경망)과 머신러닝과의 차이점
: 머신러닝을 수행할 때는 직접 데이터를 파악하고, 그 특징에 맞는 특성(feature)들을 설계하고 찾아내었지만,
딥러닝(신경망 학습)은 데이터에서 필요한 특성들을 신경망이 알아서 조합하여 찾아낸다!
즉 우리는 최소한의 데이터에 대한 전처리는 해야 하지만 특성들을 찾아낼 필요가 없다.
: 깊은 신경망, 즉 딥러닝과 머신러닝의 차이는 표현학습(representation learning)에 있다.
딥러닝은 데이터 특성 우리가 풀고자 하는 문제를 풀기 쉽도록 표현(representation)하도록 학습하는 능력이 있다
(4) 활성함수 (Activation Function)
: 인공신경망에서 활성화 함수는 다음 층으로 신호를 얼마만큼 전달할지를 결정
: 전달함수(transfer function)라고도 함

예제) Python으로 신경망 학습
https://github.com/khalidpark/deeplearning_whitepaper/blob/main/deep_learning_whitepaper_2.ipynb
khalidpark/deeplearning_whitepaper
Examples for the Deep Learning White Paper. Contribute to khalidpark/deeplearning_whitepaper development by creating an account on GitHub.
github.com
예제) Iris 데이터를 퍼셉트론으로 분류하는 예제
https://github.com/khalidpark/deeplearning_whitepaper/blob/main/deep_learning_whitepaper_3.ipynb
khalidpark/deeplearning_whitepaper
Examples for the Deep Learning White Paper. Contribute to khalidpark/deeplearning_whitepaper development by creating an account on GitHub.
github.com
1-2. 역전파, 경사하강법
(1) 비용, 손실, 에러
: 신경망의 성능을 측정하기 위해서는 '비용함수'를 계산해야 한다.
한 데이터 샘플을 Forward Propagation를 시키고 마지막 출력층을 통과한 값과 이 데이터의 타겟값을 비교하여 계산.
여기서 한 데이터 포인트에서의 손실을 'loss'라 하고 전체 데이터 셋의 loss를 합한 개념을 'cost'라고 한다.
(2) 역전파 알고리즘 (Back Propagation)
: 수학적 이해



예를들면, y = ax 에서 a 는 기울기 (x의 변화량에 따른 y의 변화량)
대입하면, Error = av1 에서 a 는 (v1의 변화량에 따른 Error의 변화량)
(=> 경사하강법에 의해 a의 기울기가 가장 최소가 되는 지점을 찾는 것이 목표)
theta Error / theta v1 의 최소값을 구할때 바로 계산할 수 있는 변수가 주어지지 않았기 때문에 '체인룰'을 통해 나누어 계산한다

위의 역전파계산 원리를 이해했다면, 동일한 원리로 계산됨을 알수있다.
(3) 경사하강법과 변형들
: Error를 줄이기 위해서는 경사(Gradient)를 계산해서 경사가 작아지도록 가중치를 업데이트해야 한다

: 기존 경사하강법은 배치(batch)방법인데, 모든 관측치를 가지고 기울기를 다 계산한 다음에 가중치를 업데이트.
이 방법은 데이터가 많아질 수록 가중치 업데이트를 위한 계산이 많아지기 때문에 학습이 느려지는 단점이 있다
: 확률적 경사하강법 (SGD) _ 무작위로 뽑은 하나의 관측값 마다 기울기를 계산하고 바로 가중치를 업데이트
: Momentum, NAG , Adam, 등

(4) 케라스를 이용한 실습
: 케라스는 딥러닝 모델을 만들기 위해 고수준의 구성 요소를 제공하는 모델 수준의 라이브러리
중요!!! 다음과 같은 순서로 작업됨을 기억하자
학습 데이터 로드
모델 정의
컴파일(Compile)
모델 학습(Fit)
모델 검증(Evaluate)
예제) 케라스 활용한 간단한 모델
https://github.com/khalidpark/deeplearning_whitepaper/blob/main/deep_learning_whitepaper_4.ipynb
khalidpark/deeplearning_whitepaper
Examples for the Deep Learning White Paper. Contribute to khalidpark/deeplearning_whitepaper development by creating an account on GitHub.
github.com
예제) 신경망 실습, FASHION MNIST 활용
https://github.com/khalidpark/deeplearning_whitepaper/blob/main/deep_learning_whitepaper_5.ipynb
khalidpark/deeplearning_whitepaper
Examples for the Deep Learning White Paper. Contribute to khalidpark/deeplearning_whitepaper development by creating an account on GitHub.
github.com
1-3. 신경망 프레임워크, 학습규제
(1) 딥러닝 라이브러리
: 1-1,1-2에서는 신경망에 대한 개념과 기초를 직접 코딩으로 구현했다면, 이제부터는 잘 구현되어있는 라이브러리를 적절하게 사용하는 방법을 배운다
예제) 케라스 활용한 신경망 모델
https://github.com/khalidpark/deeplearning_whitepaper/blob/main/deep_learning_whitepaper_6.ipynb
khalidpark/deeplearning_whitepaper
Examples for the Deep Learning White Paper. Contribute to khalidpark/deeplearning_whitepaper development by creating an account on GitHub.
github.com
(2) 학습규제
: Overfitting 극복을 위한 방법
EarlyStopping , Weight Decay , Dropout , Weight Constraint
Earlystopping
Weight Decay : 가중치를 감소시키는 기술
Weight Decay 속 L2 norm regularization , L1 norm regularization 개념
L1 : 쉽게 얘기해서 L1 Norm 은 벡터 p, q 의 각 원소들의 차이의 절대값의 합
L2 : L2 Norm 은 벡터 p, q 의 유클리디안 거리(직선 거리)출처: https://light-tree.tistory.com/125 [All about]

Weight Constraints : 물리적으로 Weight의 크기를 제한하는 방법
Dropout : 확률적으로 노드 연결을 강제로 끊어주는 역할
Learning rate decay
Learning rate 스케줄링
예제) 학습규제 적용
(Earlystopping , weight decay, Weight contraints, Dropout, learning rate decay , learning rate 스캐줄링)
https://github.com/khalidpark/deeplearning_whitepaper/blob/main/deep_learning_whitepaper_7.ipynb
khalidpark/deeplearning_whitepaper
Examples for the Deep Learning White Paper. Contribute to khalidpark/deeplearning_whitepaper development by creating an account on GitHub.
github.com
1-4. 파라미터튜닝, 실험기록
(1) CV (Cross Validation)
: 하이퍼 파라미터를 수정하다보면 운 좋게 좋은 파라미터들이 걸릴 수도 있겠지만, 운이 안 좋아서 틀린 하이퍼 파라미터를 선택하게 될 수도 있다.
교차 검증(CV)한다면 최종적으로 계산되는 정확도들의 분산(variance)을 줄일 수 있어서 위의 문제점을 최소화 가능하다
(2) 입력데이터 정규화
: 입력데이터를 신경망에 넣기 전에 무조건 해야하는 것은 아니나,
학습을 빠르게 해주고, 경사하강법이 지역 최적점(local optimum)에 빠질 위험을 줄여주기 때문에 하는 것을 추천
(3) 모델 자동 검증 기능
: 늘 하는 train_test_split 대신, 케라스에는 validation_data라는 편리한 기능
예제) CV 사용하는방법 , 입력데이터 정규화(StandardScaler) , 모델 자동검증기능(validation_data)
https://github.com/khalidpark/deeplearning_whitepaper/blob/main/deep_learning_whitepaper_8.ipynb
khalidpark/deeplearning_whitepaper
Examples for the Deep Learning White Paper. Contribute to khalidpark/deeplearning_whitepaper development by creating an account on GitHub.
github.com
(4) 하이퍼 파라미터 튜닝 방법
[1] Grid Search
: 조합 가능한 모든 파라미터을 검사하는 방법
: 가장 무식하지만 가장 확실한 방법이 될 수 있다
: 여러 하이퍼 파라미터의 최적값을 찾으려면 너무 많은 시간이 소요되기 때문에, 하나의 하이퍼파라미터 최적값을 찾을 때 사용하는 걸 추천
[2] Random Search
: 지정된 범위내에서 무작위로 선정된 조건들을 테스트해보고, 최상값을 찾는 방법
: Random Search는 상대적으로 중요하다고 생각되는 파라미터에 대해 탐색을 더 하고, 덜 중요한 하이퍼파라미터에 대해서는 실험을 덜 할 수 있도록 해줄수 있다.
[3] Bayesian Methods
: 베이지안 최적화는 이전 탐색 결과를 반영해서 이후의 하이퍼 파라미터 튜닝의 성능을 높이는 전략
(5) 하이퍼 파라미터 옵션들
batch_size
: 모델의 가중치를 업데이트할 때 한번에 몇개의 관측치를 보게 되는지를 결정하는 파라미터
: 너무 큰 배치 크기를 고르게 되면 한번에 모든 데이터에 대한 Loss를 계산해야 하는 문제점이 있고,
학습 속도가 빠르기 때문에 주어진 epoch 안에 가중치를 충분히 업데이트 할 만큼의 iteration을 돌릴 수 없게 됨
: 너무 작은 사이즈를 고른다면 학습에 오랜 시간이 걸리고, 추정값에 노이즈가 많이 생기기 때문에 이 역시 지양
: 배치 사이즈는 보통 32에서 시작해서 512에서 멈추는 2의 제곱수training epochs
optimization algorithms
learning rate
momentum
activation functions
dropout regularization
hidden layer의 neuron 갯수
예제) 배치사이즈테스트, 하이퍼파라미터튜닝(KERAS TUNER)
https://github.com/khalidpark/deeplearning_whitepaper/blob/main/deep_learning_whitepaper_9.ipynb
khalidpark/deeplearning_whitepaper
Examples for the Deep Learning White Paper. Contribute to khalidpark/deeplearning_whitepaper development by creating an account on GitHub.
github.com
(6) 실험기록 프레임워크 (wandb)
: 왜 실험기록을 해야하는가?
: epoch이 끝날 때마다 데이터가 해당 툴들에 보내지고, 모델이 수렴하고 있는지 확인할 수 있다.
https://github.com/khalidpark/deeplearning_whitepaper/blob/main/deep_learning_whitepaper_10.ipynb
khalidpark/deeplearning_whitepaper
Examples for the Deep Learning White Paper. Contribute to khalidpark/deeplearning_whitepaper development by creating an account on GitHub.
github.com
https://wandb.ai/khalidpark/deeplearning_whitepaper?workspace=user-khalidpark
khalidpark/deeplearning_whitepaper
Weights & Biases project
wandb.ai
NLP
2-1. NLP를 위한 텍스트 전처리
(1)NLP란?
: NLP(Natural Language Processing)에서 "Natural Language" 란 사람들이 일상 샐활에 사용하는 언어
자연어는 프로그래밍 언어보다 훨씬 비구조적인 특성
(2) 용어정리
: 코퍼스(Corpus, 말뭉치)란 특정한 목적을 가지고 수집한 텍스트 데이터
: 문서(Document)란 문장(Sentence)들의 집합
: 문장(Sentence)이란 여러개의 토큰(단어, 형태소 등)으로 구성된 문자열
: 어휘집합(Vocabulary)는 코퍼스에 있는 모든 문서, 문장을 토큰화한 후 중복을 제거한 토큰의 집합
(3) NLP 파이프라인

(4) 텍스트 토큰화(Tokenization)
: 트리밍 : 코퍼스에서 통계적인 방법을 통해 단어를 제거하는 방법
: 표제어추출 , 어간추출 : 예를 들어 'batteries' 와 'battery'를 보면 이 둘은 어근(root)이 같은 단어를 추출하는 방법
예제) 아마존 리뷰를 사용한 전처리, 토큰화, 토큰분석, 불용어, 불용어확장,
통계적 트리밍(trimming), 표제어추출(lemmatization), 어간추출(stemming)
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepapaer_11.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
2-2. 텍스트 벡터화
(1) 텍스트 데이터의 벡터화
: 텍스트를 컴퓨터가 사용할 수 있게 수치정보로 변환하는 것
: 2-1에서 단어들을 토큰화 했다면, 이번에는 토큰화한 정보들을 컴퓨터의 언어체계 속으로 넣어준다는 개념
(2) Bag-of-Words(BoW)
: 우리가 사용하는 언어모델을 단순화 시킨 모델
: 문서, 문장들에서 문법, 즉 어떤 단어들의 순서 등의 개념을 제거하고 단순히 단어들의 빈도만 고려하는 모델
: 문서를 토큰화한 후 토큰의 빈도를 기반으로 벡터화
예제)
(1) BBC Dataset을 이용한 spacy token, CounterVectorizer, TfidfVectorizer 및 파라미터튜닝
(2) 유사도를 이용한 문서검색 (TF-IDF 벡터거리를 이용한 방법 , K-NN을 이용한 방법)
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepapaer_12.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
(3) 어떻게 분류 모델을 선택해야 하는지 구글에서 수행한 여러 실험 결과를 가지고 제공한 가이드

(4) 잠재의미분석 (Latent Semantic Analysis, LSA)
: Word2Vec, BoW 등의 방법론을 사용해 만든 문서-단어행렬(DTM) 데이터의 차원을 축소해 문서들에 숨어있는(latent) 의미(Topics)를 끌어내는 방법
: 차원 축소에는 Truncated SVD(특이값 분해)를 사용해 원하는 문서나, 단어의 차원을 축소

예제)
데이터 : 20개 뉴스그룹으로 분류된 18,000개의 뉴스그룹 문서 데이터셋
(1) 베이스모델 : TF-IDF 모델
(2) 차원축소: Truncated SVD (특이값분해)
(3) 분석 : MLP (Multi-layer perceptron classifier)
*LSA는 SVD를 통해 찾아진 topic들을 가지고 문서와, 단어의 잠재적인 의미를 분석하는 것
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepapaer_13.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
2-3. 임베딩, Word2Vec, RNN, LSTM, GRU
(1) 요약
: 임베딩은 자연어를 컴퓨터가 이해할 수 있도록 벡터의 형태로 바꾸는 과정
: word2Vec 는 CBOW 와 skipgram 방법이 있으며, CBOW는 주변단어로 타겟단어를 예측하고, 반대로 skipgram은 타겟단어로 주변단어를 예측하는 방법
: RNN은 순환하는 신경망으로, 순환하면서 발행하는 문제를 해결하기 위해 gate를 추가한 LSTM 과 GRU가 보편적
(2) 카운트 기반 방법과의 차이점
: 카운트 기반 방법으로 만든 단어 벡터보다 단어 간의 유사도를 잘 측정하며 단어들의 복잡한 특징도 잘 잡아냄.
: Word2vec으로 만들어진 단어 벡터는 서로에게 유의미한 관계를 측정할 수 있다

(3) 임베딩
: BoW는 단어의 존재 여부와 그 빈도 정보를 중요하게 다루는 대신
단어의 순서 정보를 무시하여 단어 주변 문맥정보를 잃어버린다는 단점 존재
: 임베딩 방법중 하나인 Word2Vec은 문장에서 인접한 단어들의 정보를 중요시 하여 벡터화할 때 문맥 정보를 보존
: 임베딩이란? 연어를 컴퓨터가 이해할 수 있는 수의 나열인 벡터 형태로 바꾸는 과정 또는 결과를 의미
(4) Word2Vec
: Word2Vec은 구글 연구팀이 발표한(Mikolov et al., 2013) 기법으로 가장 널리 쓰이는 단어 임베딩 모델 중 한 가지
: skip-gram과 CBOW 두 모델 제안

(5) 분포가설
: 분포가설은 비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 지닌다는 것
: 예를들어, (I found good stores & I found bad stores.) 에서 good과 bad은 주변에 분포한 문맥 단어들이 매우 유사함으로 추축하건데 비슷한 의미를 지닐 것이다 라고 가정하는 것
(6) Word2Vec __ Skip-gram
: 입력으로 원핫인코딩된 단어벡터가 들어오고 출력부분에서는 입력단어와 다른 모든 단어들이 문맥 단어일 확률값을 계산

: 예를 들어, (window size = 2)
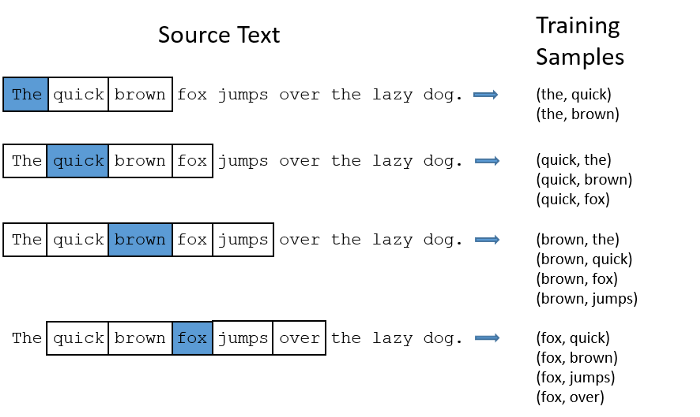
(7) Word2Vec __ CBOW(Continuous Bag of Words)
: CBOW는 skip-gram과 반대로 주변에 있는 문맥단어들을 가지고 타겟 단어 하나를 맞추는 과정을 통해 학습
: 예를 들어 입력이 (jumped, the, lake) 일 때 타겟 단어로 'into' 를 예측하며 학습
: 구조적으로 Skip-gram이 같은 코퍼스를 사용했을 때 더 많은 학습 데이터를 만들어 낼 수 있기 때문에 임베딩 결과의 품질이 CBOW 보다 좋은 것으로 알려져 있음.
예제)
: spacy를 통한 임베딩 , PCA를 사용한 벡터 시각화
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepapaer_14.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
(8) 중간정리
: Bag-of-Words 모델 중 단어의 출현 빈도를 사용해 텍스트 문서를 벡터로 변환하는 CounterVectorizer,
문서별 단어의 빈도를 계산해 가중치를 적용한 TfidfVectorizer를 사용해 봄
: 이렇게 변환된 벡터는 코사인 유사도와 같은 방법을 통해 문서들 간 유사성을 수치로 나타낼 수 있다.
문서들이 많을 때 코사인 유사도를 다 적용해서 가장 가까운 문서를 찾는 방법은 효율적이지 않다.
그래서 K-NN과 같은 트리 기반 알고리즘을 사용해 가장 가까운 K개의 문서를 빠르게 검색할 수 있다.
: Word2Vec과 같은 담어 임베딩 방법은 벡터 생성 과정 중에 문맥 정보를 보존하여 유사한 의미를 가진 단어나 문장은
유사도가 큰 벡터가 된다.
(9) RNN
: FF(Feed Foward)는 시계열(순서의 패턴에 의미가 있는) 데이터를 다루지 못함.
: 시계열의 데이터 성질(패턴)을 잡아낼 수 있는 순환신경망(RNN)
: 기본적인 신경망에 재귀(recurrent)연결을 두면서 시간축 정보를 반영할 수 있도록 만든 구조

# 배웠던 RNN을 간단한 코드로 살펴보면
import numpy as np
class RNN:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev):
Wx, Wh, b = self.params
t = np.matmul(h_prev, Wh) + np.matmul(x, Wx) + b
h_next = np.sigmoid(t)
self.cache = (x, h_prev, h_next)
return h_next
(10) LSTM (장기 단기 기억 장치) & GRU
: RNN에 Gate를 추가한 모델을 LSTM
: LSTM의 간소한 버전인 GRU


예제)
keras 를 이용한 RNN / LSTM 감정분류
LSTM 텍스트 생성기
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepapaer_15.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
2-4. Attention과 Transformer, GPT, BERT
(1) RNN의 단점
: RNN이 가진 가장 큰 단점 중 하나는 장기 의존성(Long-term dependency)
: 장기 의존성 문제란 문장이 길어질 경우 앞 단어의 정보를 잃어버리게 되는 현상
: 개선하기 위한 방법이 2-3에서 다룬 LSTM, GRU (아래이미지)
: : 하지만 문장이 길어지면, 많은 단어의 의미를 벡터 하나에 담기에 부족하기 때문에 Attention 방법이 나옴
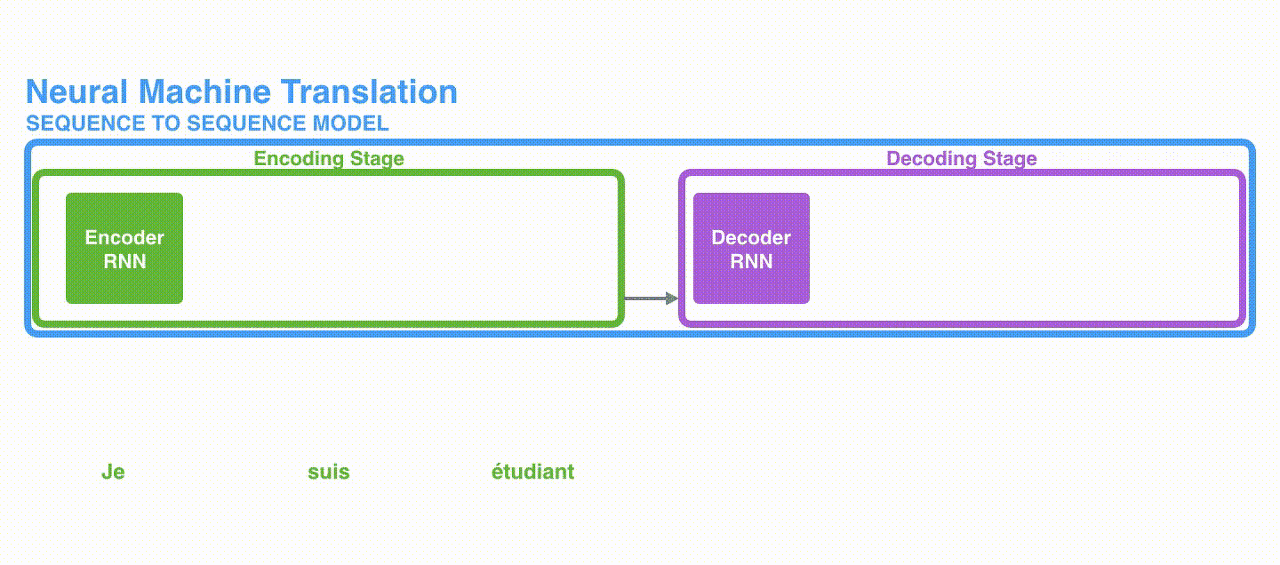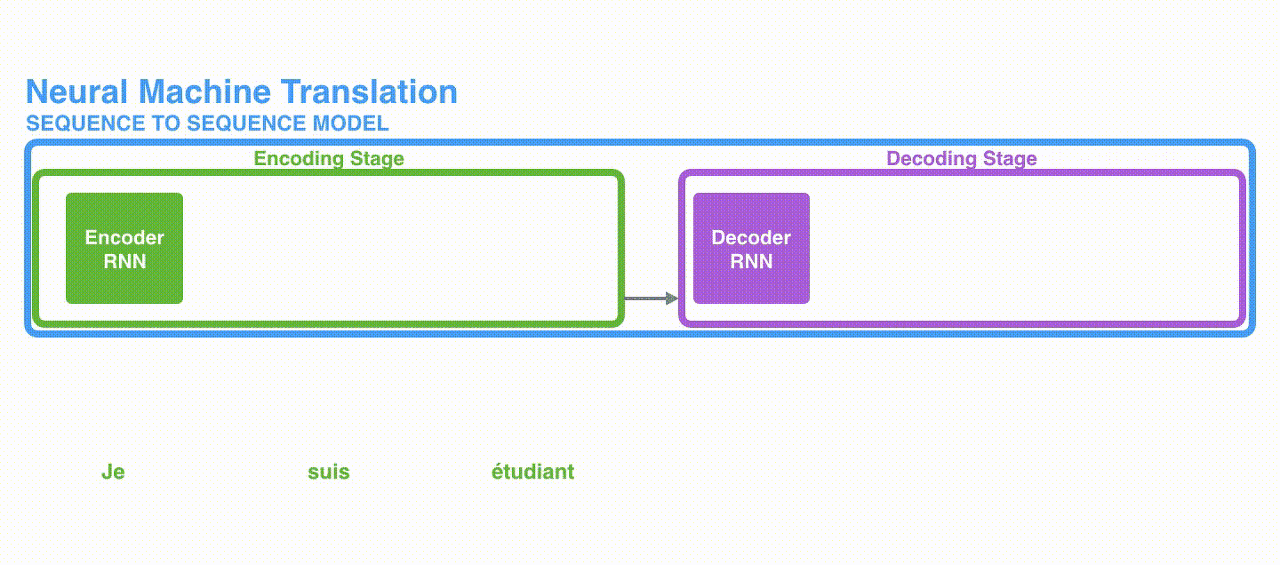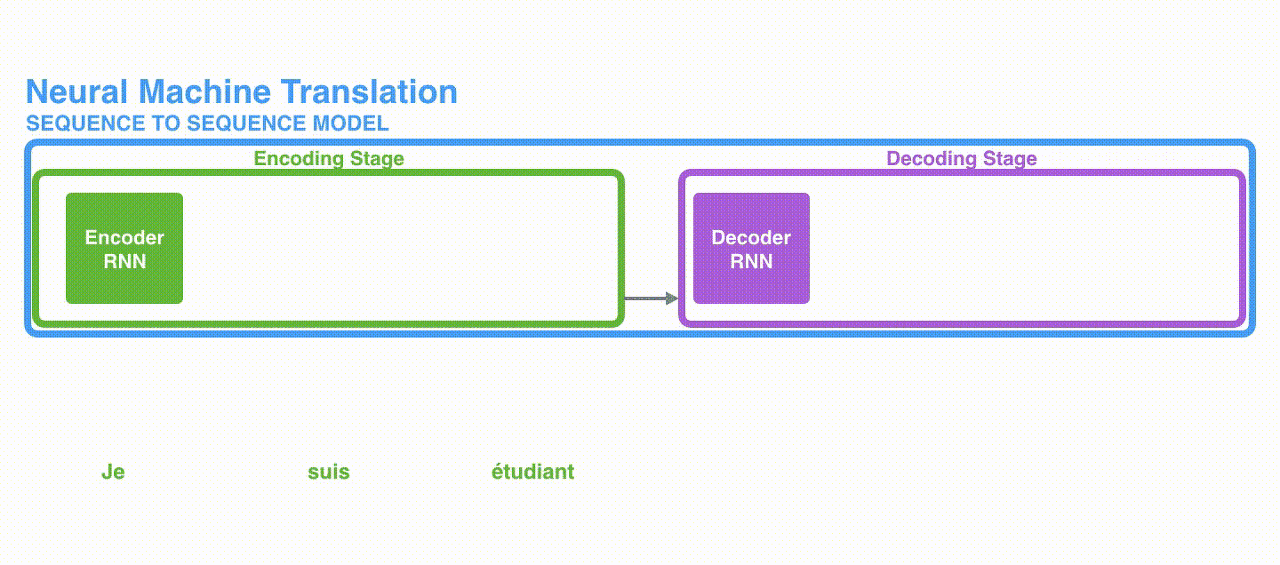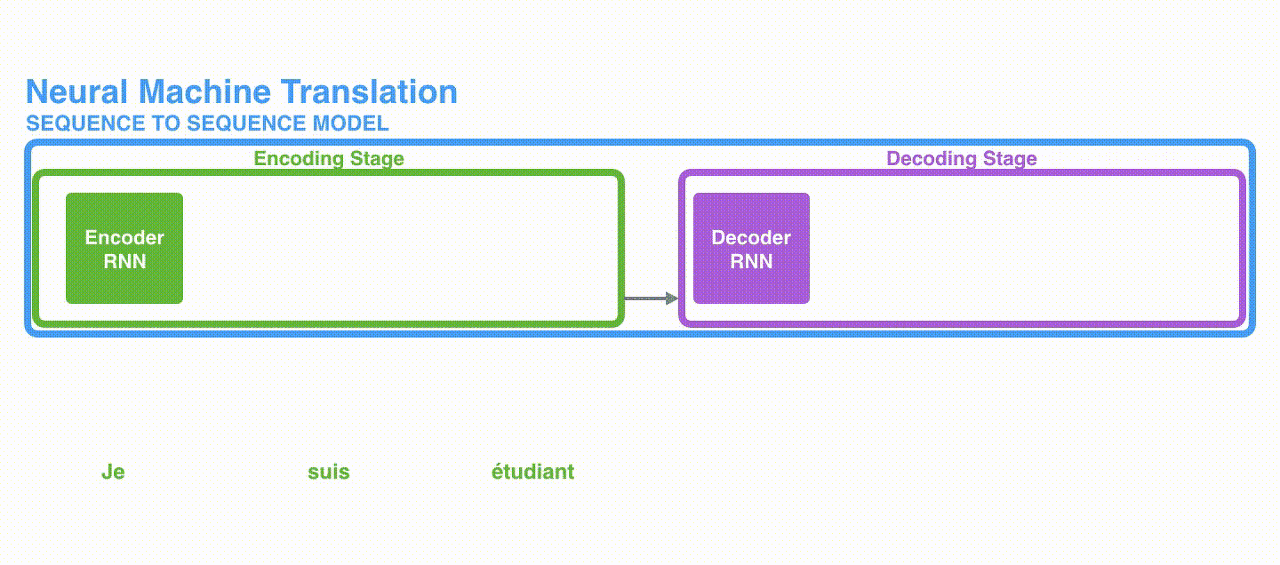
(2) Attention
: 각 인코더의 Time-step 마다 생성되는 Hidden state 벡터를 간직
: 입력 단어가 N개라면 그만큼의 Hidden state 벡터를 모두 간직
: 모든 단어가 입력되면 생성된 Hidden state 벡터를 모두 디코더에 넘겨줌

: 디코더에서는 단어를 생성할 때마다 인코더에서 넘어온 모든 Hidden state 벡터와 인코더의 각 Hidden state 벡터를 내적하여 가중치를 구하게 함.

: 디코더는 인코더에서 넘어온 모든 Hidden state 벡터에 대해 위와 같이 계산
: 그렇기 때문에 Time-step마다 출력할 단어(Target word)가 어떤 Hidden state 벡터와 연관이 있는 지,
(즉 어떤 단어에 집중(Attention)할 지를 알 수 있음)
: 이런 과정을 거쳐 단어를 생성하면 인코더에 입력되는 모든 단어의 정보를 활용할 수 있다.
(즉, 장기 의존성 문제를 해결할 수 있음)
: 예시로 제시되었던 문장(Je suis etudiant => I am a student)을 번역했을 때 각 단어마다의 Attention 스코어를 시각화

예제)
Attention 구현 코드
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepapaer_16.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
(3) Transformer
: Attention을 적용하였든 그렇지 않든, RNN 기반 모델이 가진 특징은 단어가 순서대로 들어온다는 점
=> 처리해야 하는 시퀀스가 길수록 연산 속도가 느려짐
: 트랜스포머는 이런 문제를 해결하기 위해 등장한 모델로 모든 토큰을 동시에 입력받아 병렬 연산하기 때문에
단어가 입력되기를 기다리지 않아도 된다는 장점이 있음
(4) 트랜스포머의 구조

(5) Positional Encoding (위치 인코딩)
: 트랜스포머에서는 모든 단어가 동시에 입력되므로 단어의 위치 정보를 제공하기 위해 벡터를 따로 제공해줘야함
: 단어의 상대적인 위치 정보를 제공하기 위한 벡터를 만드는 과정을 Positional Encoding 이라고 함.
(6) Self-Attention
: 트랜스포머의 주요 메커니즘
: 번역하려는 문장 내부 요소의 관계를 잘 파악하기 위해서 문장 자신에 대해 어텐션 메커니즘을 적용
: 3가지 가중치 벡터 (쿼리(Query), 키(Key), 밸류(Value)) 를 이용하여 단어 사이의 관계를 파악
=> 쿼리(q)는 분석하고자 하는 단어에 대한 가중치 벡터
=> 키(k)는 각 단어가 해당 쿼리와 얼마나 연관있는 지를 비교하기 위한 가중치 벡터
=> 밸류(v)는 각 단어의 의미를 살려주기 위한 가중치 벡터
def scaled_dot_product_attention(q, k, v, mask):
"""Calculate the attention weights.
q, k, v must have matching leading dimensions.
k, v must have matching penultimate dimension, i.e.: seq_len_k = seq_len_v.
The mask has different shapes depending on its type(padding or look ahead)
but it must be broadcastable for addition.
Args:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable
to (..., seq_len_q, seq_len_k). Defaults to None.
Returns:
output, attention_weights
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# scale matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# add the mask to the scaled tensor.
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# softmax is normalized on the last axis (seq_len_k) so that the scores
# add up to 1.
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
(7) Multi-Head Attention
: Self-Attention 을 동시에 여러 개로 실행하는 것
: 각 Head 마다 다른 Attention 결과를 내어주기 때문에 앙상블과 유사한 효과
(8) Layer Normalization & Skip Connection
: 트랜스포머의 모든 sub-layer에서 출력된 벡터는 Layer normalization과 Skip connection을 거치게 됨
: Layer normalization의 효과는 Batch normalization과 유사. 학습이 훨씬 빠르고 잘 되도록
: Skip connection(혹은 Residual connection)은 역전파 과정에서 정보가 소실되지 않도록
(9) Feed Forward Neural Network
: 은닉층의 차원이 늘어났다가 다시 원래 차원으로 줄어드는 단순한 2층 신경망
: 활성화 함수(Activation function)으로 ReLU를 사용
(10) Masked Self-Attention
: 디코더 블록에서 사용되는 특수한 Self-Attention
: 디코더는 Auto Regressive 하게 단어를 생성하기 때문에 타깃 단어 이후 단어를 보지 않고 단어를 예측해야 함
: 따라서 타깃 단어 뒤에 위치한 단어는 Self-Attention에 영향을 주지 않도록 마스킹(masking)을 해주어야 함.

(11) Encoder-Decoder Attention
: 디코더에서 Masked Self-Attention 층을 지난 벡터는 Encoder-Decoder Attention 층으로 들어감.
: 좋은 번역을 위해서는 번역할 문장과 번역된 문장 간의 관계 역시 중요하며 두 문장간의 관계를 엮어주는 부분
: 이 층에서는 디코더 블록의 Masked Self-Attention으로부터 출력된 벡터를 쿼리(Q) 벡터로 사용
: 키(K)와 밸류(V) 벡터는 최상위(=6번째) 인코더 블록에서 사용했던 값을 그대로 가져와서 사용
: Encoder-Decoder Attention 층의 계산 과정은 Self-Attention 했던 것과 동일
Encoder-Decoder Attention 가 진행되는 순서를 나타낸 이미지

(12) Linear & Softmax Layer
: 디코더의 최상층을 통과한 벡터들은 Linear 층을 지난 후 Softmax를 통해 예측할 단어의 확률을 구하게 됨
예제)
Transformer 코드실습
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepapaer_17.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
(13) GPT & BERT
: GPT와 BERT는 트랜스포머 구조의 일부분을 변형하여 만들어진 언어 모델
: 두 모델은 사전 학습된 언어 모델(Pre-trained Language Model) 이라는 공통점
: 사전 학습이란 대량의 데이터를 사용하여 미리 학습하는 과정이며,
여기에 필요한 데이터를 추가 학습시켜 모델의 성능을 최적화하는 방법 (전이학습Transfer Learning)이라고도 함.
(14) GPT (Generative Pre-Trained Transformer)

(15) BERT
: BERT는 트랜스포머의 인코더만을 사용하여 양방향(Bidirectional)으로 읽어냄
: BERT 역시 GPT 와 동일한 Pre-trained LM 이기 때문에 Pre-training과 Fine-tuning 과정을 통해 학습
: BERT의 사전학습
=> 2가지 방법 (MLM, NSP)
=> MLM (Masked Language Model)
=> BERT는 사전 학습 과정에서 레이블링 되지 않은 말뭉치 중에서 랜덤으로 15%가량의 단어를 마스킹
그리고 마스킹된 위치에 원래 있던 단어를 예측하는 방식으로 학습을 진행
=> NSP (Next Sentence Prediction)
=> 모델이 문맥에 맞는 이야기를 하는지 아니면 동문서답을 하는지 아닌지를 판단하며 학습하는 방식
3-1. CNN
(1) 뉴럴 네트워크 복습


(2) CNN을 이용한 다양한 사례들
: 사물인식 - Object Detection (YOLO) + RCNN(Fast, Faster, MASK RCNN)
: 포즈예측 - Pose Estimation (PoseNet)
: 윤곽분류 - Instance Segmentation (Detectron)
: 기타 등등
(3) Convolution의 이해
: CNN은 컨볼루션(Convolution)을 적용하여 시각적 접근 방식을 모방한다.
: 1-D Convolution

: 2-D Convolution
=> 이미지의 노란색 부분으로 변하는 부분이 Convolution filter와 만나는 부분
=> 그렇게 연산이 되었을 때, 분홍색의 output 값을 얻을 수 있다.
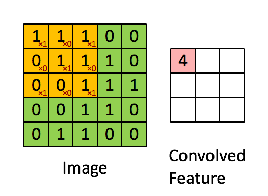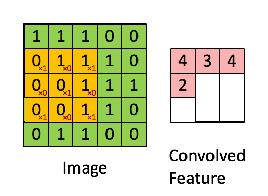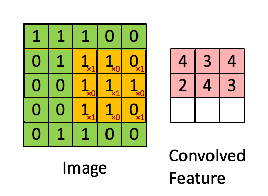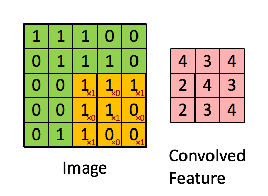

=> zero padding이란?
=> padding 흰색 pixel의 경우는 실제 이미지가 있는 부분이고,
짙은 회색의 pixel은 feature map의 크기 조절과 데이터를 충분히 활용하기 위해 가장자리에 '0'을 더해준 것
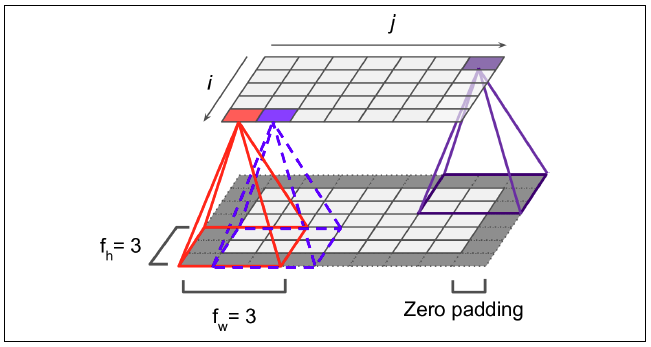
=> Stride이란?
=> 성큼성큼 걷다는 표현의 단어 뜻, 한번에 얼만큼씩 걸을 것인지 나타내는 의미


: 용어설명
=> Filter : 가중치 (weights parameters)의 집합으로 이루어져 가장 작은 특징을 잡아내는 창
=> Stride : 필터(filter)를 얼만큼씩 움직이며 이미지를 볼 지 결정하는 수
=> Padding: Zeros(또는 다른 값)을 이미지의 외각(가장자리)에 배치하여 conv를 할 때
원래 이미지와 같은 데이터의 수를 갖을 수 있도록 도와줌 (Stride = 1일 때)
예제) 2D Conv 함수 정의
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepapaer_18.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
예제)
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepapaer_19.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
(4) Convolution in Action

예제) Cifar10
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepapaer_20.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
(5) 전이학습 (Transfer Learning)

: 기존(내 목적과는 다른) 데이터로 학습된 네트워크를 재사용 가능하도록하는 라이브러리
: 수천 시간의 GPU로 학습된 모델을 다운받아 내 작업에 활용할 수 있음
: 가중치(Weights)와 편향(bias)이 포함된 학습된 모델의 일부를 재사용하기에 Transfer learning 이라고 표현
: 위 그림처럼 일부만 사용을 해서 활용할 수도 있지만, 전체를 다 재학습할 수도 있습니다.
: 사용하는 방법
=> 이전에 학습한 모델에서 파라미터를 포함한 레이어를 가져옴
=> 향후 교육 과정 중에 포함된 정보가 손상되지 않도록 해당 정보를 동결(freeze, 가중치를 업데이트 하지 않음)
=> 동결된 층 위에 새로운 층 (학습 가능한 층)을 더함
=> 출력층(output)의 수를 조절하여 새로운 데이터셋에서 원하는 예측방법(분류, 회귀 등)으로 전환
=> 새로운 데이터셋에서 새로 추가한 계층만을 학습
=> 만약 기존 레이어를 동결하지 않으면, 학습된 레이어에서 가져온 weight까지 학습하게 됨
=> 위 경우 학습할 것이 많아지므로 시간이 오래 걸림
예제) ResNet 50
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepapaer_21.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
3-2. Image Segmenatation
(1) 이미지 분할
: 이미지 분할은 이미지를 픽셀 단위의 마스크를 출력하도록 신경망를 훈련시키는 것

예제)
Oxford-IIIT Pets 이용한 이미지 예측
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepapaer_22.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
(2) 데이터 증강(Data Augmentation)
: 이미지 회전과 같은 무작위(그러나 사실적인) 변환을 적용하여 훈련 세트의 다양성을 증가시키는 기술
: 방법1 Keras 전처리 레이어 사용 / 방법2 tf.image 사용
(3) 객체 인식 (Object Recognition)
: 사전 학습된 이미지 분류 신경망을 사용하여 다중 객체 검출
=> CNN 가운데 레이어의 출력 결과인 피쳐 맵 위에 슬라이딩 윈도우를 올린다.
=> 사전 학습된 신경망은 해당 이미지의 클래스를 반환한다.
=> 만약 이미지에서 서로다른 객체가 검출되면 확률값을 둘로 쪼개서 반환한다.
=> 하나의 객체만 나오더라도 충분한 활률값이 아니면 분할하여 반환한다.
: 다중객체를 찾는 방법의 하나는 이미지 위에 슬라이딩 윈도우를 올리고 윈도우 내에서 단일 객체 검출을 시도하는 것
: 이미지를 224x224로 다운 샘플링 하는 대신에 원본을 두배로 을려 448x448로 샘플링한다
: 그 다음 Crop된 이미지를 만들어 분류기에 넣는다
예제) 방법1, 방법2 후 객체인식
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepaper_23.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
3-3. Auto Encoder
(1) 오토인코더 개요
: 오토인코더(Autoencoders)는 비지도학습 방식으로 효율적인 데이터 코딩(encoding, decoding)을 학습하는 데 사용
: 오토 인코더의 목적은 네트워크가 신호 "노이즈"를 무시하도록 훈련함으로써
일반적으로 차원 감소를 위한 데이터세트에 대한 잠재적 표현(Latent representation)을 학습하는 것
: 데이터 차원의 축소(encoding)와 축소된 데이터에서 다시 재구성(decoding)하는 가중치들이 학습
: 오토인코더를 이용하면 노이즈를 제거할 수 있고, 노이즈가 제거된 데이터의 특징값을 추출하는 추출기로도 사용가능
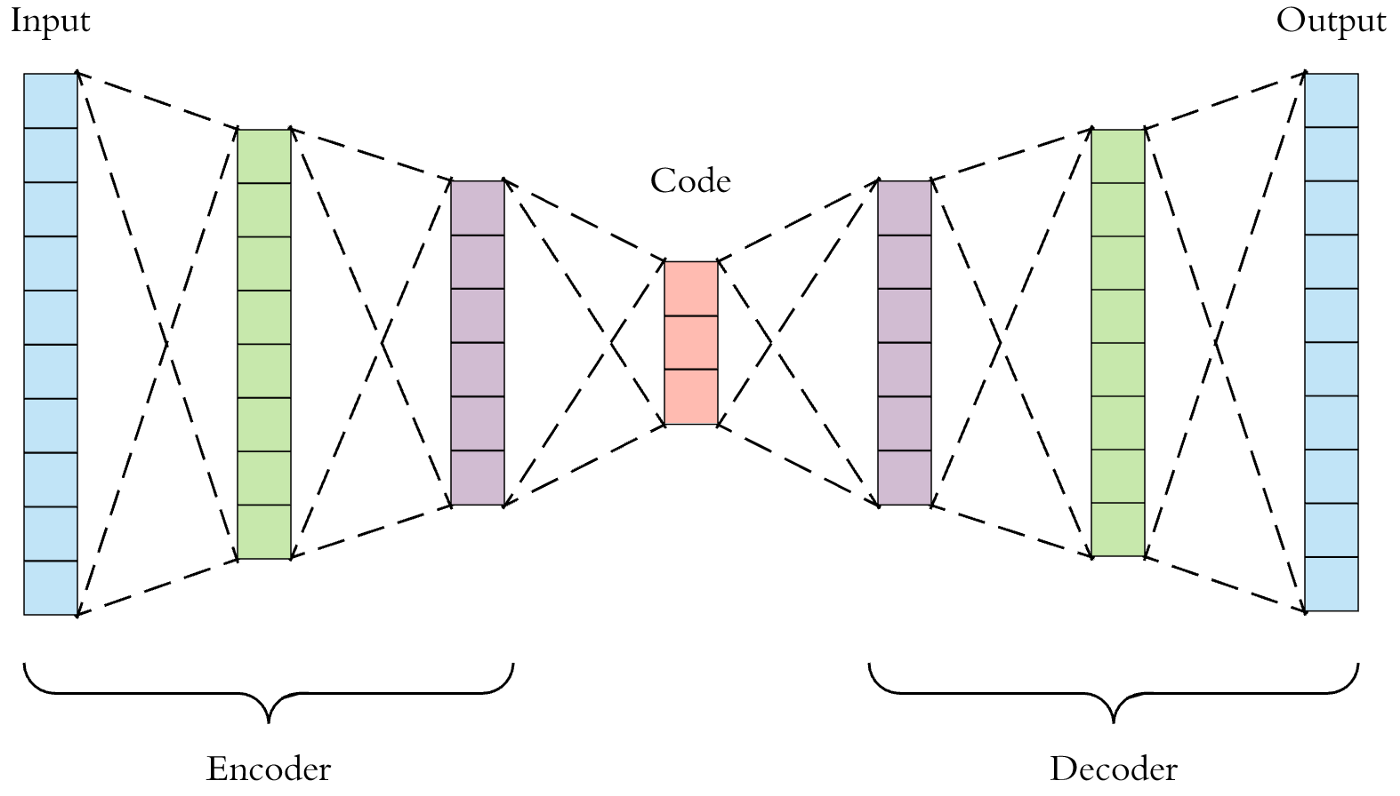
예제) 실습1,실습2
기본 오토인코더, 노이즈제거용 오토인코더

https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepaper_24.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
예제) 실습3
이상현상발견용 오토인코더
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepaper_25.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com
3-4. GAN
(1) 의미
: 생성적 대립 신경망(GANs) 을 인공지능 화가"제작에 적용해보면, Creator/Generator ("AI화가")는 진짜 작품처럼 보이는 이미지를 생성하도록 배우게 되고, 동시에 Descriminator ("AI감별사")는 인공지능이 만든 가짜의 이미지들과 진짜를 예술작품을 구별하게 되는 것을 배우게 되는 원리
: 훈련과정 동안 Generator는 점차 실제같은 이미지를 더 잘 생성하게 되고, Descriminator는 점차 진짜와 가짜를 더 잘 구별하게됩니다. 이 과정은 Descriminator가 가짜 이미지에서 진짜 이미지를 더이상 구별하지 못하게 될때, 평형상태에 도달한다

예제) DCGAN 실습
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepaper_26.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com

예제) CycleGAN 실습
https://github.com/khalidpark/whitepaper-DeepLearning/blob/main/deep_learning_whitepaper_27.ipynb
khalidpark/whitepaper-DeepLearning
Examples for the Deep Learning White Paper. Contribute to khalidpark/whitepaper-DeepLearning development by creating an account on GitHub.
github.com

(2) Pix2Pix
Pix2Pix란 Conditional Adversarial Network를 이용하여 Image-to-Image Model
참고 : https://wjddyd66.github.io/tnesorflow2.0/Tensorflow2.0(1)/
Pix2Pix
Pix2PixCode 참조: Tensorflow pix2pix논문 참조: Image-to-Image Translation with Conditional Adversarial NetworksPix2Pix가 뭔지에 대해서 자세히 알아보기 전에 먼저 Pix2Pix의 결과부터 살펴보자.Pix2Pix란 Conditional Adversarial
wjddyd66.github.io
pix2pix.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
출처 : 코드스테이츠


댓글